Data Quality and Data Governance: What Leaders Must Fix Before Scaling AI
- Jun 18, 2026
- Isha Taneja
Understand how data quality and governance affect AI success, and discover the key issues leaders must solve before scaling AI systems.

Understand how data quality and governance affect AI success, and discover the key issues leaders must solve before scaling AI systems.

AI projects do not fail only because of weak models.
They often struggle because the data underneath them is incomplete, outdated, inconsistent, poorly controlled, or owned by nobody.
A model may perform well during a controlled pilot. But once it connects with more users, systems, and real business processes, hidden data problems begin to appear.
Predictions become unreliable. Teams disagree over definitions. Sensitive information reaches the wrong people. Nobody knows who should correct the problem.
This is why leaders must address both data quality and data governance before scaling AI.
The difference is simple:
Data quality determines whether AI can trust the data. Data governance determines who owns, controls, protects, and is accountable for that data.
An organisation needs both.
Clean data without governance can create privacy, security, and ownership risks. Strong governance around inaccurate data only creates well-controlled information that nobody can trust.
Although data quality and governance work together, they solve different problems.
Data quality | Data governance |
Measures whether data is reliable | Defines how data should be managed |
Checks accuracy and completeness | Assigns ownership and responsibility |
Identifies duplicates and inconsistencies | Controls access and permitted use |
Improves trust in decisions | Creates accountability |
Detects data problems | Defines who must resolve them |
Consider a customer database containing duplicate records.
Data quality measures the number of duplicates and determines whether they are affecting reports, customer communication, or AI recommendations.
Data governance identifies the customer data owner, defines the approved customer record, assigns responsibility for correcting the duplicates, and establishes rules to prevent the problem from returning.
Quality provides the evidence. Governance creates accountability.
AI systems learn from, retrieve, combine, and process data. When the underlying information is unreliable, the output can also become unreliable.
A model may perform well during testing because it is working with a limited and carefully prepared dataset. Problems often appear when the system is exposed to new customers, changing business conditions, unusual cases, and live data pipelines.
IBM reported in January 2026 that concerns about data accuracy and bias were a leading barrier to scaling AI for 45% of surveyed business leaders.
NIST also identifies harmful bias and other data quality issues as factors that can affect the trustworthiness of AI systems.
This means data quality is no longer only a technical responsibility. It is now a business, leadership, risk, and customer trust issue.
Leaders should assess six core data quality dimensions:
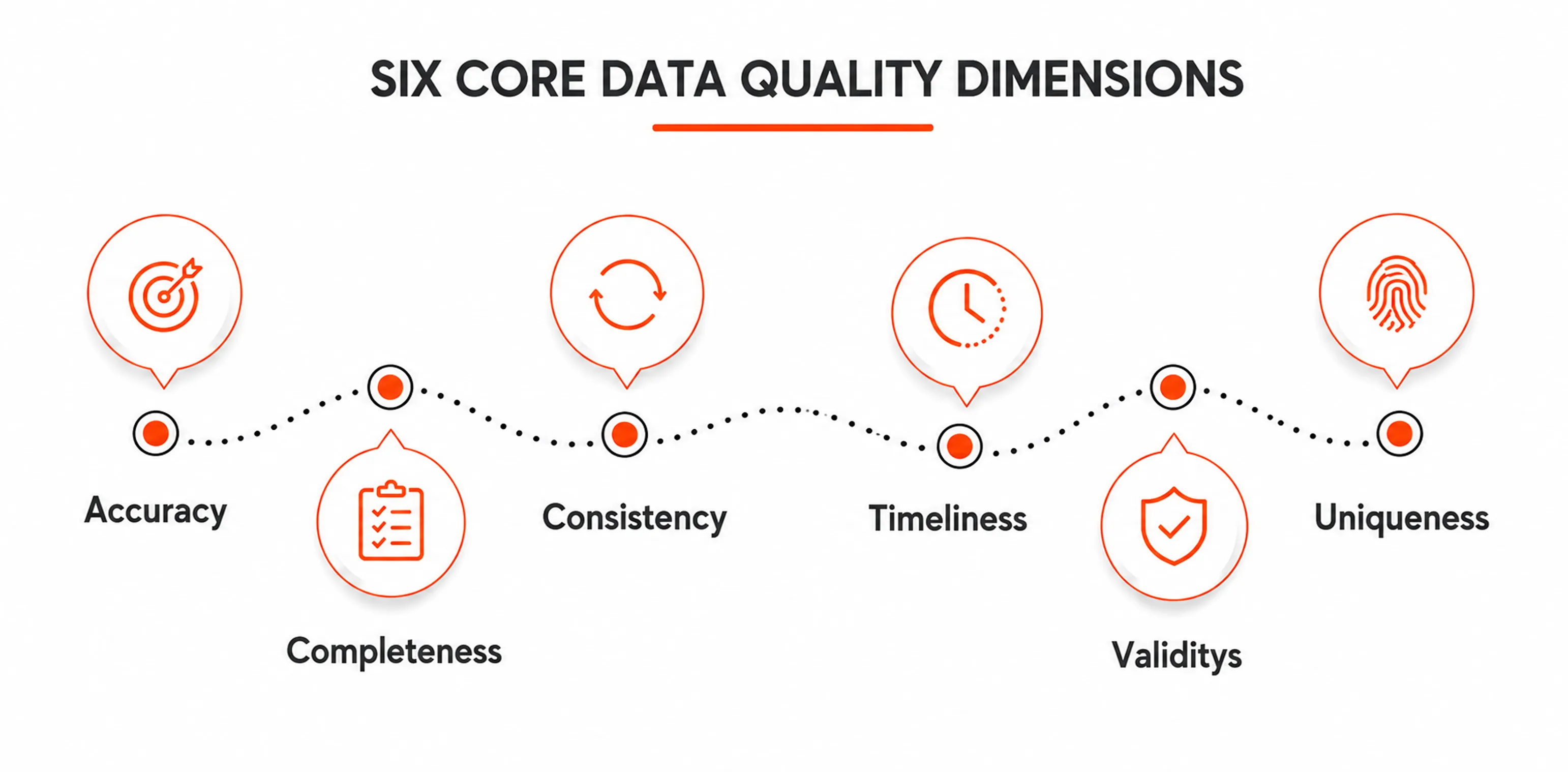
Accuracy: Data correctly represents reality.
Completeness: Important information is not missing.
Consistency: Data matches across systems.
Timeliness: Data is updated when needed.
Validity: Data follows the correct format and rules.
Uniqueness: Duplicate records are removed.
For AI systems, leaders must also consider bias, relevance, representation, label accuracy, and data noise.
A dataset can be technically clean but still be unsuitable for AI if it excludes important customer groups, regions, languages, or business situations.
Not every data error carries the same business risk.
A missing optional customer preference may have little effect on an AI recommendation. However, an incorrect consent status, transaction value, medical code, fraud indicator, or eligibility field could create serious consequences.
This is why leaders should not measure data quality through one general score.
Quality thresholds should be based on the decision the AI system supports.
For every critical field, teams should understand:
What happens if the value is missing?
What happens if it is incorrect?
How quickly must it be updated?
Which AI output depends on it?
Who is responsible for correcting it?
For example, 95% data completeness may look impressive on a dashboard.
But if the missing 5% includes the fields that determine customer eligibility, financial risk, or access rights, the dataset may still be unsuitable for AI.
The most valuable data quality metric is not simply the total number of errors.
It is the potential effect of those errors on customers, decisions, compliance, revenue, and business operations.
Many AI teams receive data from existing applications, warehouses, or external providers and assume it has already been validated. However, data prepared for dashboards and reports may not meet the stricter requirements of AI systems.
Missing values, duplicate records, incorrect labels, unusual patterns, transformation errors, and historical bias can all affect model performance. Before approving an AI initiative, teams should verify where the data came from, how it was transformed, what limitations it carries, and whether it is suitable for the intended use.
Training data should be verified before deployment, not after unreliable results appear.
AI systems often combine information from sales, finance, marketing, operations, and customer service. The same term may have a different meaning in each department.
For example, sales may define an active customer as someone who purchased within 30 days, while marketing may use 90 days. Customer service may consider every open account active.
Each definition may be valid within its own department. The problem begins when an AI system combines them without recognising the difference. Leaders should establish shared business definitions and identify an approved source for every critical data field.
Without common definitions, even accurate data can produce confusing results.
A data problem without an owner rarely gets solved permanently.
Every important data domain, including customer, product, employee, patient, financial, or supplier data, should have someone accountable for its meaning, quality, access, and correction.
The owner should approve business definitions, set quality expectations, resolve conflicts between systems, prioritise corrections, and escalate serious issues when necessary.
Technology can identify a problem. Clear ownership ensures that someone acts on it.
Data quality can change even after an AI system has been deployed.
A source application may change its format, a field may stop updating, a business rule may be revised, or a pipeline may begin sending incomplete records. This is why checking data only during the pilot stage is not enough.
Organisations should continuously monitor completeness, duplication, freshness, consistency, validation failures, unresolved issues, and correction time. These measurements show whether data quality is genuinely improving or simply appeared reliable during a controlled test.
Many organisations purchase data quality management tools before clearly defining the problems they need to solve.
Data quality tools generally support profiling, validation, anomaly detection, cleansing, monitoring, and remediation. Data governance tools focus more on ownership, lineage, cataloguing, classification, policies, access control, and audit records.
AI systems may also require schema monitoring, data drift detection, training data lineage, sensitive information detection, and model input monitoring.
Some platforms offer several of these capabilities, but tools should always be evaluated against the organisation’s actual requirements.
Technology can support data quality and governance, but it cannot replace clear definitions, ownership, policies, or accountability.
Leaders do not need to create a complicated programme before beginning an AI project. They need a clear process connected to the business use case.
Define the decision, workflow, or customer problem the AI system will support.
Clarify who will use the output, what could happen if the output is wrong, and whether human review is required.
Document every database, application, API, file, external provider, pipeline, and transformation feeding the AI system.
Teams should understand where the data originated and how it changed before reaching the model.
Set acceptable standards for accuracy, completeness, consistency, timeliness, validity, and uniqueness.
These thresholds should reflect business risk.
A field used for financial, clinical, legal, or security decisions may require a much stricter standard than an optional marketing field.
Identify the business owner, technical owner, and data steward responsible for every critical data domain.
Also define who will correct issues and how unresolved problems will be escalated.
Define who can access the data, how it may be used, whether it contains sensitive information, how long it should be retained, and who can approve a new use case.
Governance should guide the AI project from the beginning rather than appear as a final approval step.
Track data quality, pipeline failures, schema changes, drift, access violations, and correction times after deployment.
AI readiness is not a one-time certification. It must be maintained as data and business conditions change.
Data quality and data governance are different disciplines, but neither can support AI effectively in isolation.
Data quality determines whether information is accurate, complete, consistent, timely, valid, representative, and usable.
Data governance determines who owns that information, who can access it, how it should be protected, and who must act when a problem appears.
Reliable AI requires both.
The strongest AI foundation is not created by purchasing the most advanced model. It is created through trusted data, shared definitions, measurable standards, clear ownership, appropriate controls, and continuous monitoring.
Before scaling the AI layer, make sure the data foundation can support the decisions the system will influence.
Is your data foundation ready for AI?
Complere Infosystem helps organisations improve data quality, establish practical governance, modernise data pipelines, and prepare enterprise data for responsible AI deployment.
Listen in for business strategies and interviews with business experts to help you build a business and a life that you love.
About Us


